The basic idea is that we want to combine web archives with an
existing large language model, so that the model will answer questions
using the contents of the web archive as well as its inherent
knowledge. I have for many years run a wiki for myself and a few
friends, which has served variously as social venue, surrogate memory,
place to pile up links, storehouse of enthusiasms. When Matteo first
announced WARC-GPT, it struck me that the wiki would be a good test;
would the tool accurately reflect the content, which I know well?
Would it be able to tell me anything surprising? And more prosaically,
could I run it on my laptop? Even though the wiki is exposed to the
world, and I assume has been crawled by AI companies for inclusion
into their models (despite the presence of a restrictive robots.txt),
I don’t want to send those companies either the raw material or my
queries.
This month, the Library Innovation Lab celebrated the full and unqualified release of the Caselaw Access Project data. We took the opportunity to gather and look to the future at Transform: Justice on March 8th. The event reminded us of what we already knew: the open legal data movement is alive and well.
The Library Innovation Lab is excited to announce that the original limitations on the data available for the Caselaw Access Project expired this month, and that data can now be fully released without restriction on access or use.
As part of our original collaboration agreement with Ravel Law, Inc. (now part of LexisNexis) for the Caselaw Access Project there had been access limitations on the full text and bulk data available, which have now expired. Over the next few months, we will be partnering with other organizations in the open legal data space like the Free Law Project to shepherd this data into its next phase. The Free Law Project already includes all CAP cases, as well as cases scraped from court websites, in its CourtListener search engine.
We will continue hosting the CAP data in bulk for researchers, and as individual readable cases, at case.law. However, we will be winding down services that can be better provided elsewhere, such as the search function and API.
This post is part of the Library Innovation Lab’s announcements in the context of Transform: Justice, celebrating the full, unqualified release of the data from the Caselaw Access Project.
When the Lexis corporation first launched legal research terminals in the 1970s it hoped to “crack the librarian barrier,” allowing lawyers to do their own legal research from their desks instead of sending law firm librarians through paper search indexes. Today something larger is possible: we may be able to “crack the justice barrier,” allowing people to answer a larger and larger number of legal questions for themselves. According to the Legal Services Corporation, low-income Americans do not receive any or enough legal help for 92% of their civil legal problems, so there would be a huge public benefit to making legal resources more widely available.
We want academics and nonprofits at the table in discovering the next generation of legal interfaces and helping to close the justice gap. It is not at all clear yet which legal AI tools and interfaces will work effectively for people with different levels of skill, what kind of guardrails they need, and what kind of matters they can help with. We need to try a lot of ideas and effectively compare them to each other.
That’s why we’re releasing a common framework for scholarly researchers to build novel interfaces and run experiments: the Open Legal AI Workbench (OLAW). In technical terms, OLAW is a simple, well-documented, and extensible framework for legal AI researchers to build services using tool-based retrieval augmented generation.
We’re not done building this yet, but we think it’s time to share with the legal technology and open source AI communities for feedback and collaboration.
Out of the box, OLAW looks like this:
Video: OLAW’s chatbot retrieving court opinions from the CourtListener API to help answer a legal question. Information is interpreted by the AI model, which may make mistakes.
What is OLAW for?
OLAW itself is not a useful legal AI tool, and we didn’t build it to be used as-is. Instead, OLAW is intended to rapidly prototype new ideas for legal tools. OLAW is an excellent platform for testing questions like:
How are legal AI tools affected by the use of different prompts, models, or finetunings?
How can legal AI tools best incorporate different data sets, such as caselaw, statutes, or secondary sources?
What kind of search indexes are best for legal AI tools (boolean, semantic search etc.)?
How can users be best instructed to use legal AI tools? What interface designs cause users at different skill levels to engage with the tool effectively and manage its limitations?
What kind of safety guardrails and output filters are most effective and informative for legal AI tools?
What kind of information about the tool’s internal processes should be exposed to users?
What kind of questions are better or worse suited for legal AI tools, and how can tools help guide users toward effective uses and away from ineffective ones?
… and many others. If you want to experiment with legal AI search tools, and you have a programmer who can write some basic Python, OLAW will give you all the knobs to turn when you get started.
Why is OLAW needed now?
Legal AI tooling is a wide-open design space with the potential to help a lot of people. We want to make it easier for the academic and open source communities to get involved in exploring the future of these tools.
The commercial legal research industry is undergoing the fastest period of exploration since the invention of the internet. While there has been incremental progress, the boolean search techniques still used by lawyers today would be recognizable to lawyers using LEXIS terminals in the 1970s. But now, everything is changing: commercial vendors like Westlaw, LexisNexis, and vLex all introduced novel AI-based search interfaces in the last year.
We want to support research that happens outside the legal industry as well as inside, and research that is published publicly and peer-reviewed as well as proprietary. That’s needed because lots of people who need legal help may never be profitable to serve; because lots of novel tools are now possible beyond the ideas any one company can explore; and because everyone will be better off if there is rigorous, public research available on what works and what doesn’t.
What’s next?
We currently have the core concept implemented: a simple, well documented testbed using tool-based retrieval augmented generation that is easy to modify. These are some directions we would like to explore next:
Automatic benchmarking frameworks. OLAW currently requires manual testing to evaluate the impacts of design experiments. Some impacts may be testable automatically; we would like feedback on the best way to design effective benchmarks.
Additional tools. OLAW ships with just one tool, which runs searches against the CourtListener API. We would welcome additions of default tools that search other legal resources.
Structured extension points. We have a standard plugin-based approach to adding tools, but other extensions such as output filters or display methods require patches to the underlying source code. We would like help identifying other extension points that would benefit from standardized interfaces for testing.
We welcome the community’s input on these and other areas for improvement.
How do I get involved?
OLAW is currently best suited for programmers who can host their own web software and make their own modifications. To get started, head over to our GitHub repo to get installation instructions, file issues, send pull requests, or comment in the discussion area.
Credits
Thanks to Jeremiah Milbauer and Tom Zick for their input on this effort; all mistakes are by Jack and Matteo.
How do you make the invisible visible? This is the central premise of The Cloud, a project that I’ve been working on as a technologist in residence at LIL. The idea originated as a visual joke about the cloud: the vaporous metaphor we use to describe the distributed servers that host remotely-run software and infrastructure.
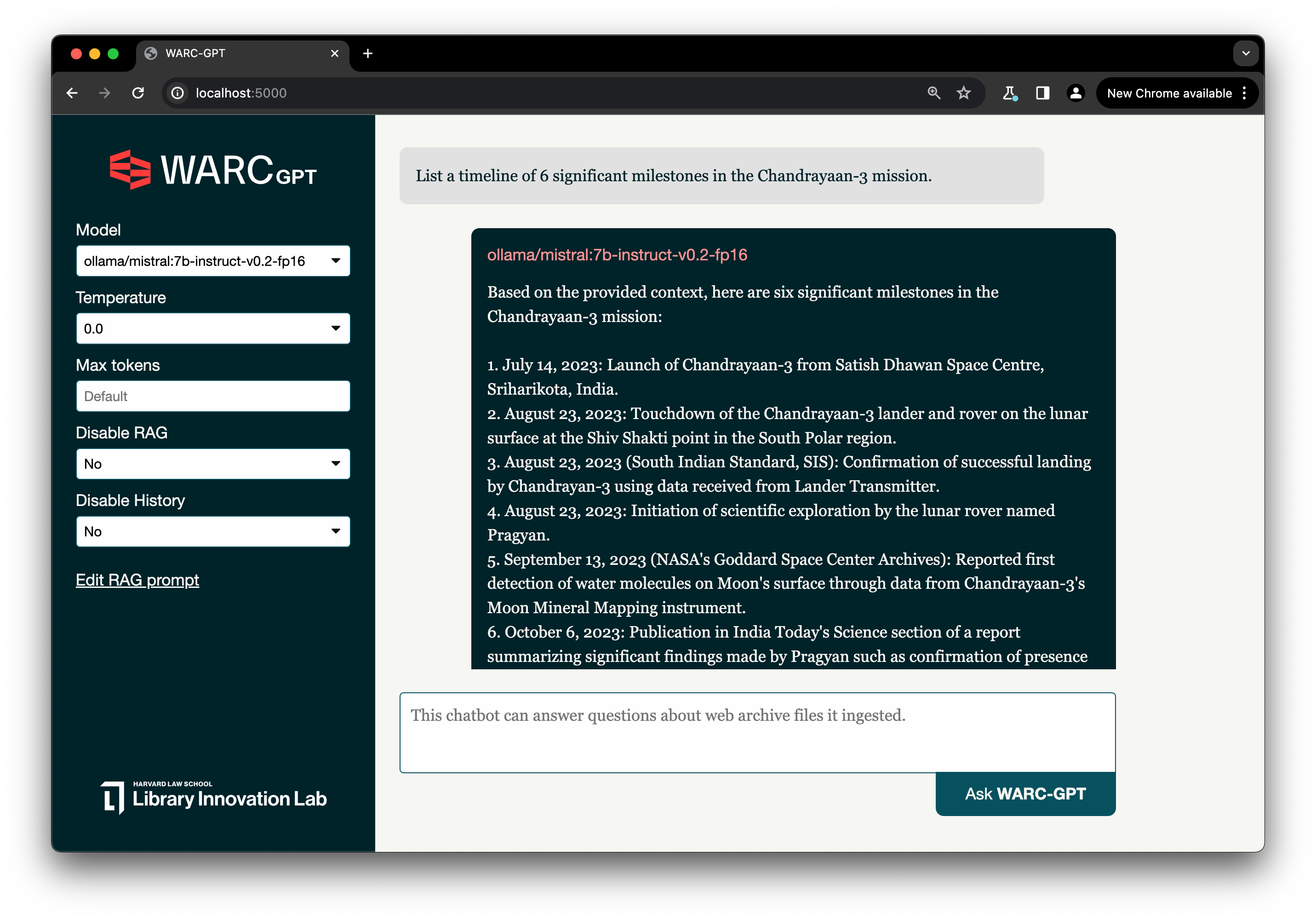
Today we’re releasing WARC-GPT: an open-source, highly-customizable Retrieval Augmented Generation tool the web archiving community can use to explore the intersection between web archiving and AI. WARC-GPT allows for creating custom chatbots that use a set of web archive files as their knowledge base, letting users explore collections through conversation.
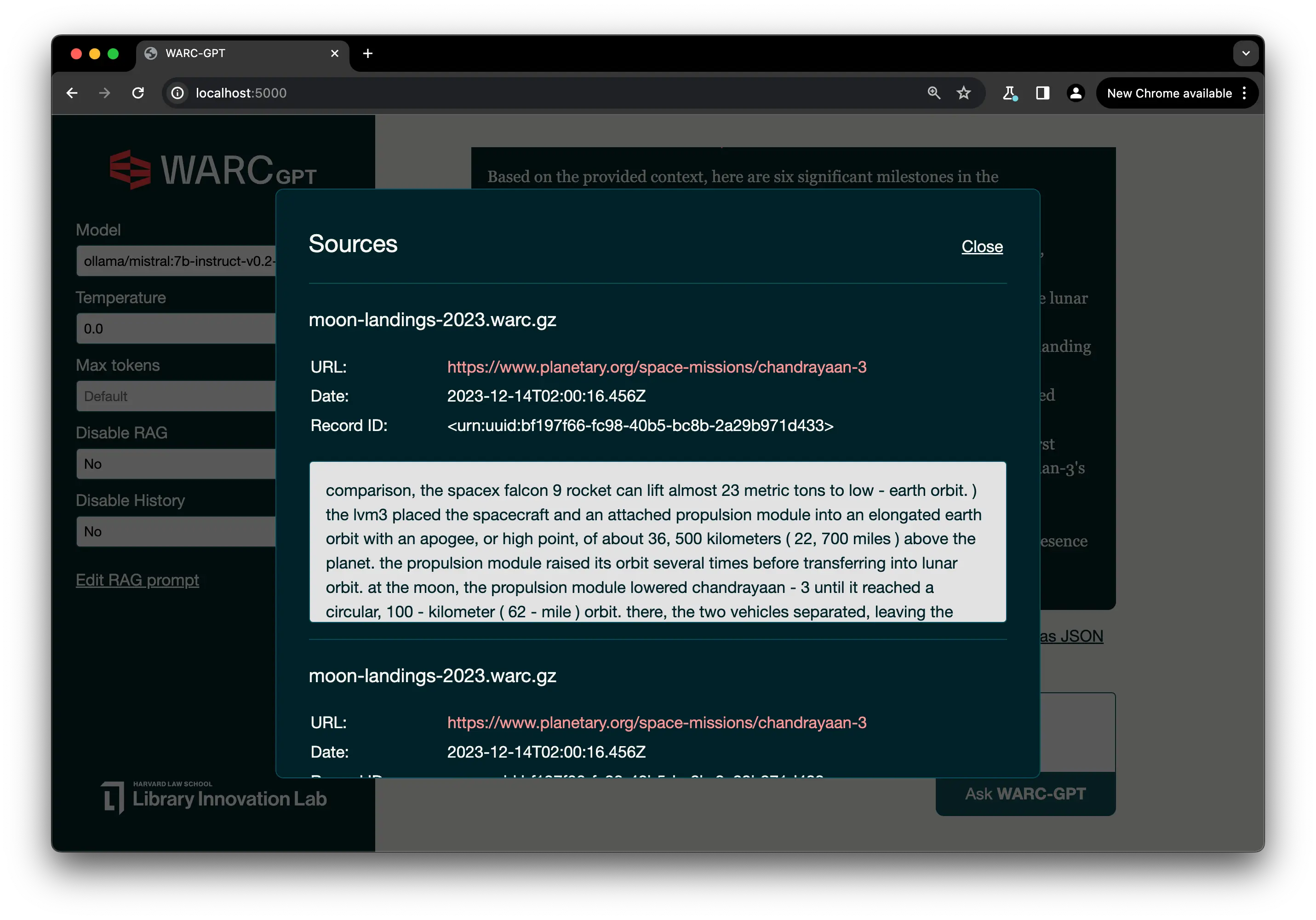
Using WARC-GPT, you can ask specific questions in natural language against a collection of WARC files. Rather than relying on keyword searches and metadata filters to sort through search results, WARC-GPT provides a new starting point for search using multi-document full-text search with summarization to explore the contents of web archives. WARC-GPT lists the sources used to generate the response and relevant text excerpts, which you can use to verify the information provided and identify points of interest within a collection of web archives.
Screenshot: WARC-GPT answering a question using a web archives collection as its knowledge base.
Screenshot: “Show sources” panel of WARC-GPT, displaying the excerpt of WARC records it used to generate a response.
If you want to run WARC-GPT yourself, head over to Github for installation instructions. If you are a library professional, researcher or tinkerer who wants to understand Retrieval Augmented Generation and how it can apply to specialized digital archives like web archives, read on.
At LIL, we’ve been providing users with the ability to preserve online sources via Perma.cc since 2013. Running a digital archive puts us in the “forever business”–what’s online today may be gone tomorrow, but that Perma Link you saved should never expire. Promising to host something forever brings with it different challenges than hosting something for a month or a year. There are the technical burdens: How will we guarantee these links stay accessible even as the underlying technologies continue to develop? There are logistical concerns: Where will we put all these files? There’s also a question of cost: Just how much does it cost to store a file forever?
The LIL team is excited to welcome Katy Gero, who joins us to investigate ethical language models for creative writing. Katy is a post-doc at the Variation Lab at Harvard SEAS, which is led by friend of LIL Elena Glassman.
Here is a picture of the Statue of Liberty doing a TikTok dance, as painted by van Gogh, as interpreted by ChatGPT. This is very relevant to my point and we’ll come back to it.
One of the best ways to think about large language models is as universal, personal translators. When I gave a talk at a Spanish-language library conference in Argentina recently, it was an excellent chance to test what LLMs currently offer as translators and what they might become. The answer made me optimistic for how LLMs can work as humanistic knowledge tools, in concert with library values.
This piece is adapted from a keynote talk I gave at Innovación y Experiencia del Usuario at Universidad Católica de Argentina on November 1, 2023.
I was asked to give a talk on the subject of “disruptive innovation in libraries,” which isn’t necessarily the phrase I would choose to describe our work, but I enjoyed using that lens to explore the changes all libraries are going through.
If you want to skip around, Part 1 explores the disruptive changes libraries are experiencing with the arrival of the internet over the last forty years; Part 2 proposes a new mission for libraries in reweaving cultural memory for the internet age; and Part 3 outlines what I’ve learned so far about leading “disruptive innovation” within large, established institutions.
When I think about disruptive innovation in libraries I think about two stories.